Music generation with GRUs
Introduction
Hello, and welcome to my blog! I wanted to share with you a mini-project that’s been on my mind for some time.
You see, I have a huge collection of MIDI files from various bands that I’ve used to learn guitar (actually, they’re Guitar Pro files, but converting them to MIDI is easy enough). With such musical data, I knew there was potential for an interesting machine learning project. There are countless things to explore, such as genre classification or instrument recognition, but I decided to focus on music generation.
For my project, I selected one of my all-time favorite bands: Megadeth. I began by extracting each track from the MIDI files, ending up with a lot of guitar, bass, and drum tracks from over 100 songs (but with some repetition). Realizing that a single model might struggle to generate all the instruments simultaneously, I decided to start by generating drum tracks and then move on to guitar and bass.
I opted for a recurrent neural network architecture featuring layers like LSTMs or GRUs, which are well-suited for sequence-based tasks such as music generation.
So, let’s dive in!
Data Preprocessing
As mentioned earlier, my starting point was a vast collection of Megadeth MIDIs. Before feeding this data into my model, I needed to convert the MIDI files into a suitable numerical representation. This involved transforming the raw MIDI files into sequences of notes represented by a matrix of numbers. To accomplish this, I chose to use the piano roll representation.
The piano roll representation is an intuitive way to visualize and process MIDI data. In a piano roll, the horizontal axis represents time, while the vertical axis corresponds to the pitch of the notes, much like the keys on a piano. Each note is represented by a rectangular bar, where the position of the bar on the vertical axis indicates its pitch, and the length of the bar corresponds to the note’s duration.
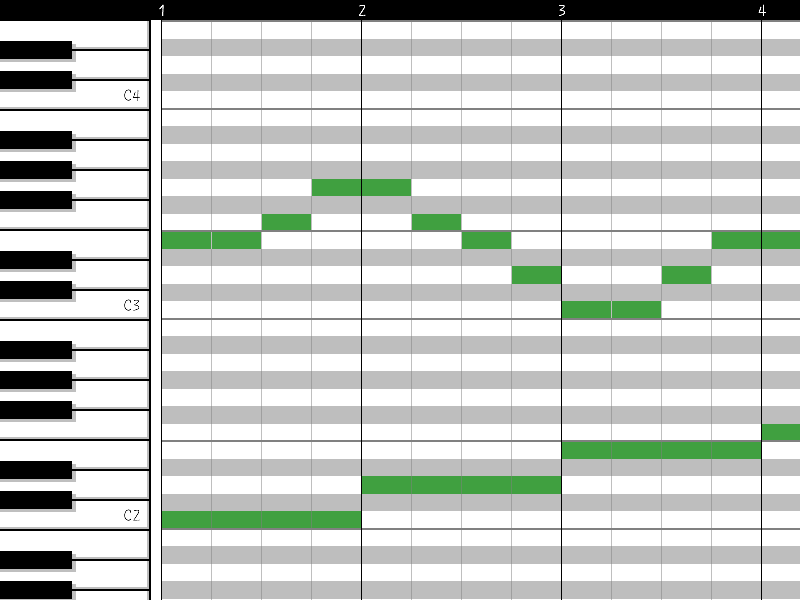
Getting to this representation is easy with the pretty_midi library
def midi_to_piano_roll(midi_file, fs=16):
midi_data = pretty_midi.PrettyMIDI(midi_file)
piano_roll = midi_data.get_piano_roll(fs=fs)
return piano_rollIn our format, each note is represented as a one-hot encoded vector of size 128. By selecting an appropriate sequence length, we can create the input data needed for our model. This format allows the model to understand and generate new music based on the patterns it detects in the input sequences.
With the data preprocessed and ready to go, we can now move on to defining and training the model and generating some new midis!
Model
After extensive experimentation with various architectures, I finally settled on a configuration that included a single GRU layer followed by a couple of Dense layers:
input_shape = (sequence_length, 128)
model = Sequential()
model.add(GRU(units=2048, input_shape=input_shape, return_sequences=True))
model.add(Dropout(0.5))
model.add(TimeDistributed(Dense(2048, activation="sigmoid")))
model.add(Dropout(0.3))
model.add(TimeDistributed(Dense(128, activation="sigmoid")))
model.compile(loss="binary_crossentropy", optimizer="adam")_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gru (GRU) (None, 96, 2048) 13381632
dropout (Dropout) (None, 96, 2048) 0
time_distributed (TimeDistr (None, 96, 2048) 4196352
ibuted)
dropout_1 (Dropout) (None, 96, 2048) 0
time_distributed_1 (TimeDis (None, 96, 128) 262272
tributed)
=================================================================
Total params: 17,840,256
Trainable params: 17,840,256
Non-trainable params: 0
_________________________________________________________________
To ensure that the model’s performance is monitored, I added a callback to track the F1 metric, which I find relevant for this task:
def on_epoch_end(epoch, logs):
y_pred = np.argmax(model.predict(X_val) > 0.5, axis=2)
y_true = np.argmax(Y_val > 0.5, axis=2)
f1 = f1_score(y_true.ravel(), y_pred.ravel(), average='macro')
print(f"\nEpoch {epoch + 1} - F1-score on validation set: {f1:.4f}")With the model architecture and callback in place, the training step is quite straightforward:
model.fit(X_train,
Y_train,
validation_split=0.2,
epochs=1000,
batch_size=128,
callbacks=[f1_callback, early_stopping], verbose=1)Once the training is complete, it’s time to generate some new music. I accomplish this by feeding the model a random sequence from the input data (though you could create your own sequence if you prefer) and repeatedly prompting the model to make predictions:
def generate_sequence(model, seed_sequence, output_length):
generated_sequence = seed_sequence.copy()
sequence_length = seed_sequence.shape[0]
for _ in range(output_length):
input_sequence = np.array([generated_sequence[-sequence_length:]])
next_step_probs = model.predict(input_sequence)[0]
next_step = (next_step_probs > 0.5).astype(np.float32)
generated_sequence = np.vstack([generated_sequence, next_step])
return np.array(generated_sequence)
# Choose a random seed sequence from the input data
seed_idx = np.random.randint(len(input_data))
seed_sequence = input_data[seed_idx]
# Generate a new sequence of desired length
output_length = 8
generated_sequence = generate_sequence(model, seed_sequence, output_length) Overall, the model performed well, and the generated MIDI files were quite interesting. If you’d like to explore the project further, you can check out the notebook here.
Future Directions
In the future, I’m ready to explore the potential of using transformers for this project. My initial attempt with transformers didn’t quite yield the desired results, it was the first thing I tried. But I’m optimistic that with some fine-tuning and experimentation, they could prove to be a powerful tool for music generation.
Another avenue to explore is the generation of complete songs, incorporating multiple instruments. This would involve training models capable of generating not only drum tracks but also guitar and bass. The challenge lies in coordinating the different instruments to produce a cohesive piece of music.
Lastly, I’m also interested in experimenting with other bands and styles, as well as combining data from multiple sources to create a more diverse training set.
Thanks for reading!